Hypothesis: How Googlebot Tracker 4200 Got External Crawl Data
My Googlebot Tracker logs crawl data from my site - and oddly, from other sites too. Here are my thoughts on why that might be happening.
I built the Googlebot Tracker 4200 tool back in March 2024 to get a better sense of how Google's crawlers actually work. Since then, it's collected roughly 55,000 rows of crawl data from my own site - but interestingly, about 50 of those rows somehow come from other (external) websites.
VIEW THE EXTERNAL CRAWL DATA HERE
While I'm not entirely sure how I got Googlebot data from other websites, I wanted to write a blog post sharing some of my hypotheses on why it might be happening.
Lets take some notes..
The first thing to note is that this website (Waraas.com) is on a dedicated IP address (198.54.114.122), which means only this site is tied to that IP. That's important because it rules out the possibility that the data is coming from a shared hosting setup.
The second thing to note is that the data is verified as coming from Google. I can confirm this by having the software run a reverse hostname check to see the hostname of the crawler's IP address.
How to Verify the Data?
Now before I get too far, I want to go over how I verify the data is actually from the Googlebot.
When a crawler like Googlebot visits this website (or any website), it leaves its IP address behind in the server logs. A reverse DNS (rDNS) lookup is a way to take that IP address and figure out the hostname associated with it. This is useful because it helps confirm that the request really came from Googlebot and not some random bot pretending to be it.
For example, an IP from Googlebot might resolve to something like crawl-66-249-66-1.googlebot.com. The googlebot.com part of the hostname is what tells us that this request is legit.
To check the hostname yourself, you can run a reverse DNS lookup using various methods:
- Command line: On Linux or macOS, you can use
host [IP]ornslookup [IP]. On Windows,nslookup [IP]works as well. - Online tools: There are many websites where you can enter an IP and it will return the hostname for you.
Another example, if you run a reverse DNS lookup on the IP 66.249.66.1, it might return crawl-66-249-66-1.googlebot.com. That's how we can verify that the tracker is actually logging real Googlebot visits and not some fake bot trying to sneak in.
Each time a Googlebot visits this website (Waraas.com), the software automatically checks and logs the hostname of the crawler's IP address. You can view the hostnames of the crawlers on the Googlebot Tracker 4200 and the external data pages.
Looking at the Data
If you look at the data, you'll notice that most of the external websites are pretty spammy. Many don't even work, and most of them are just subdomains.
A lot of the external URLs points to the /robots.txt file.
Some of the external websites do still respond, but in most cases the only thing that works is their /robots.txt file.

One thing that is confusing: if they are spamming, why are they linking to the /robots.txt file?
What Do My Server Logs Show?
Long story short, the server logs don't tell us much. That's actually one of the main reasons I built the Googlebot Tracker 4200 - they just don't capture enough data, and I wanted a lot more insight into Google's crawlers.
In the photo below, you can see the raw server log data for the "https://133-tyler-parkway.your.ke/robots.txt" website that happened on Sept 24th, 2025. The raw logs don't show much data unfortunately.
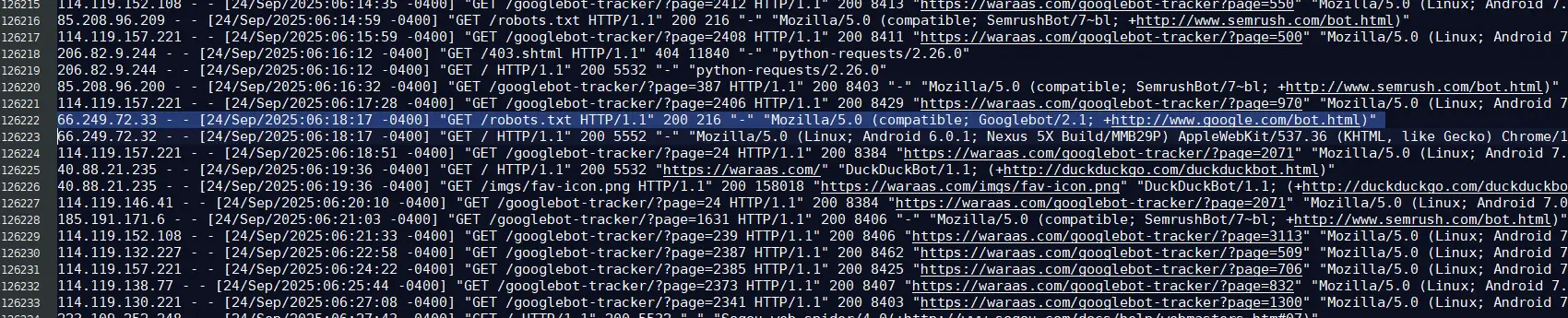
Also note that the server logs show the "GET /robots.txt" aspect looks legit. If it was external spam, then it would contain the whole URL "https://133-tyler-parkway.your.ke/robots.txt" and not just the "/robots.txt".
Let's hypothesize why we are getting external data:
Below, I'll go over some of my hypotheses on why Waraas.com is getting external Google crawl data.
1. Other domains pointed at my IP (DNS trick)
While I haven't tested this aspect yet, I'm 75% sure this is what's causing the external crawl data.
Every website has a domain name (like example.com) and an IP address (like 192.0.2.1). The DNS system basically tells browsers and bots where to send their requests. Normally, Waraas.com sits on its own dedicated IP, so only my site is tied to that address.
Anyone who owns a domain can technically point it to your IP by changing the A record. For example, someone could register external-domain.com and set its DNS A record to my server's IP.
Now, when Googlebot (or anyone) crawls that domain, the request ends up at my server. My server doesn't care that it "belongs" to someone else; it just sees a request for a URL.
Googlebot always crawls by domain, not by IP. So when it hits external-domain.com:
- It looks up the domain via DNS ? finds my IP.
- It sends an HTTP request with the host header set to external-domain.com.
- My tracker logs it as a Googlebot visit.
Since the host isn't Waraas.com, my tracker labels it as external crawl data. That's why these rows show up in the logs even though the domain isn't mine.
If this is some weird DNS spam, then why are they linking to their /robots.txt page? That's weird :/
2. Spammers
There is still a chance that my code has bugs, but I think that's unlikely.
I'm pretty confident in my Googlebot Tracker 4200 code and doubt that someone could trick the reverse hostname check.
If someone is actually doing this kind of spam, then it's pretty impressive, and I want to understand how and why it's done.
But again.. why would they be spamming their /robots.txt page, that doesn't make sense.
3. Google gone and f%^ked up
There is a slight possibility that this is actually an error on Google's end, and the crawler is sending the GET info via a proxy (whether Google's or someone else's proxy) or something.
4. Reverse proxies or redirects
If some external domains use reverse proxies or redirect traffic to my server (either on purpose or by accident), my Googlebot Tracker can pick up those requests. That's why Googlebot activity from other domains might show up in my logs.
5. Googlebot crawling from shared IP ranges
Even though Waraas.com is on a dedicated IP, Googlebot uses large IP blocks to crawl many sites. My Googlebot Tracker logs requests by IP, so sometimes external URLs can show up in the logs even if they're not part of my site.
6. Misconfigured logging or monitoring
Since my Googlebot Tracker scans logs and traffic broadly, it can sometimes pick up URLs from other domains that pass through my server, especially during tests, mirrors, or through CDN caching setups.
7. Old or cached URLs
Sometimes Googlebot crawls URLs that were once linked to my IP or domain because of cached data or old DNS records. These "phantom" URLs could end up showing up as external data in my Googlebot Tracker.
I will be running some more tests of my own and updating the code over the next few months.
One update will be to upgrade the actual Googlebot Tracker 4200 software and get even more data about the crawlers, such as the actual server info and such.
Another test I want to run is to set up a new website designed specifically for Googlebots. Over time, this will obviously help gather even more data, but it will also let me focus that site entirely on Googlebot activity, while keeping this one as my personal blog.
You can view the external crawl data here from The Googlebot Tracker 4200 yourself if you would like.
But if you have any ideas about what could be causing the Googlebot Tracker 4200 to receive external Googlebot crawl data, please leave a comment.
Thank you for reading my long rambling about Googlebots :) Who knows, maybe someone from Google will chime in?
Conversation:
Martin Macdonald
October 7th, 2025
Jon Waraas
October 7th, 2025
Conversation:
Ever since building my first website in 2002, I've been hooked on web development. I now manage my own network of eCommerce/content websites full-time. I'm also building a cabin inside a old ghost town. This is my personal blog, where I discuss web development, SEO, cabin building, and other personal musings.
