The Art of Bot War: What Are Fake Googlebots?

Why do fake Googlebots exists? And how to detect them?
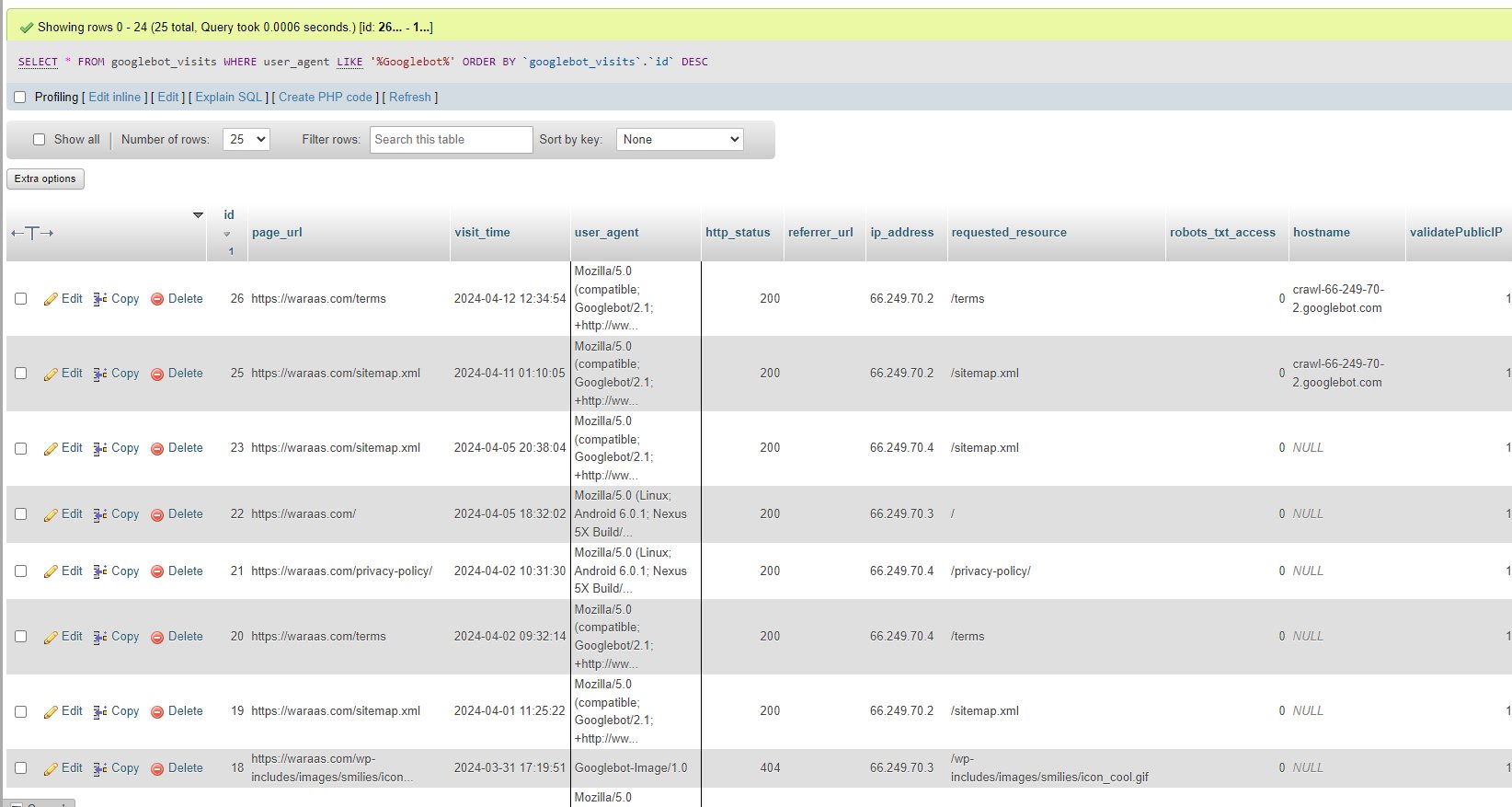
So within just a few weeks of launching the Googlebot Tracker 4200 tool, which tracks all of the Googlebot sessions on this blog (Waraas.Com), I've already encountered a fake Googlebot.
When I first coded the tool, I didn't think anyone would faking a Googlebot. So I didn't code enough "verifications" into the tool to check if the Googlebot is real or not.
Well yesterday I had to code in a "DNS lookup" into the Googlebot Tracker 4200, so it will now only track real Googlebots. That cost me about an hour of work.

But why would anyone waste the time and money to fake a Googlebot? Especially to crawl my brand spankin' new blog?
It takes a lot of time to code one of these up, not to mention the costs aspect. It's not cheap to buy non-blocked IP's and then store the crawled data on servers.
So I did some diggin, and want to share the results with you guys :)
First, what is a Googlebot?
A "Googlebot" is the generic name for Google's web crawling bots, sometimes also referred to as a spiders. These bots are automated software programs that Google uses to scan, index, and retrieve web pages on the internet to add to Google's search engine database.
The primary purpose of a "Googlebot" is to discover new and updated pages to be added to the Google index.
How Googlebot Works
Crawling: Googlebot discovers pages by following links from known pages to new pages.
Indexing: Once a page is crawled, its content is analyzed and indexed. Text content and other data from the page are processed and stored in Google's servers to be quickly retrieved when a relevant search query is made. (Note: think of Google search as a database)
Processing: Beyond just storing the page's content, Googlebot also processes components of the page such as the layout and any embedded information (like metadata or multimedia, just not flash haha).
Now, Why Do Fake Googlebots Exist?
I honestly don't know for certain. As I mentioned before, the costs make it impractical, plus the bots are very very easy to spot (I'll go over that later). Also, trying to fake a Googlebot might get their IP blocked on whatever they are trying to crawl.
In order to get any REAL data (aka lots of it) from bots, you will need a good amount of non-blocked IP addresses, and some servers to store the data on.

Cost and time wise, it's one thing if you are making a crawler that will crawl and index a few dozen websites. It's a whole other thing to crawl and index thousands upon thousands of websites.
Here are three reasons why I think fake Googlebots exist:
Spamming or Hacking: They could be used to probe websites for vulnerabilities to exploit or to distribute spam or malware.
Data Scraping: Illegitimately scraping content from websites which can then be used without permission, often violating terms of service or copyright laws.
Bypassing Security Measures: Some websites give preferential treatment to Googlebot (like allowing more frequent crawling or access to more pages). Fake bots also might impersonate Googlebot to bypass restrictions and access protected areas.
The main reason why I think the fake Googlebots exists is because of the IP aspect. From personal experience, getting a good amount of non-blocked IP addresses isn't easy or cheap.
My guess is that they are trying to trick some of the website security tools (like Cloudflare.com) that haven't caught on yet. Once they are caught, then their IP are banned and they have to get a new one in order to crawl that same website.
So I'm assuming they are trying to save money in the IP address department.
How To Detect Fake Googlebots?
Detecting a "fake" Googlebot is easy. All you have to do is a "dns lookup" to see if the IP matches up with the Google.Com domain.
You can do a simple DNS lookup by inputting the IP address here of the web crawler that you suspect of being fake.
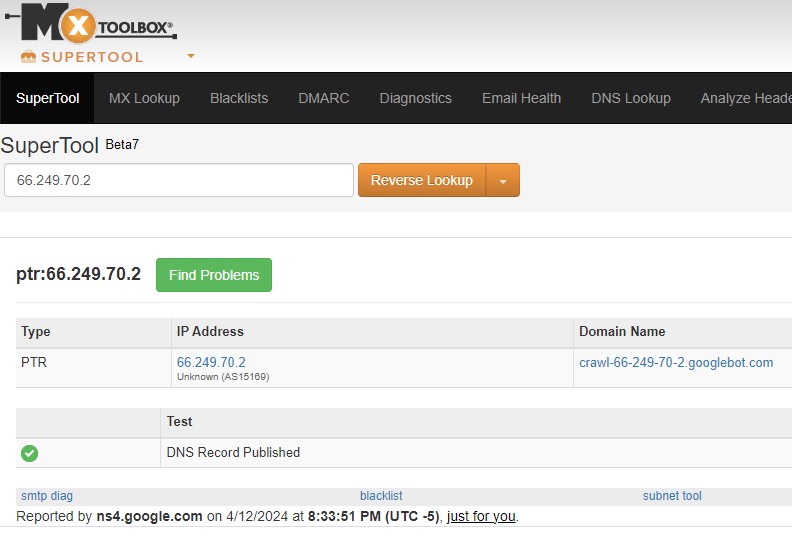
Only the a Googlebot will have the "googlebot.com" domain name as the "hostname".
So any crawler that has "googlebot" in the "user agent", but doesn't have a "googlebot.com" domain name when you do a DNS lookup, is a fake Googlebot.
How to detect a fake Googlebot crawler with php?
Its pretty easy to code up a function that will track the Googlebots. Below is the same function that I am currently using. However, I will probably be giving it another update this weekend.
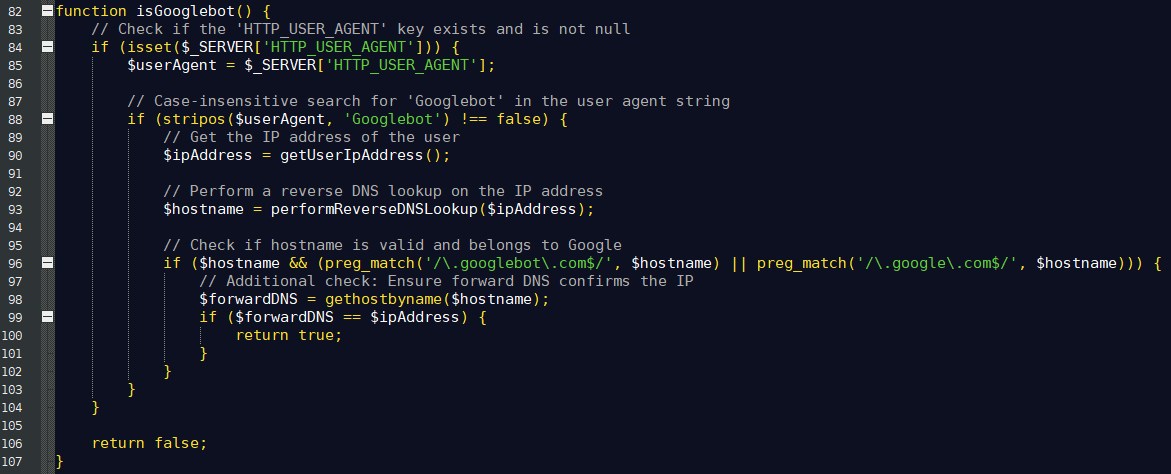
You can also take this function and make some tweaks to make it block the fake Googlebots. The fakes ones are up to no good, and are just wasting server resources.
What this function does is checks to see if the "user agent" is set. If the "user agent" is set, then it will check if the "user agent" contains the word "Googlebot". This aspect is easy to fake.
The function will then grab the users "IP address" and then use that to do a "reverse DNS lookup", which will check to see the "hostname".
Once the function has the "hostname", it will then check to make sure that the "hostname" contains the words "googlebot.com" and "google.com".
If all that matches up, then the function will get the "hostnames" IP address, and make sure that is the same "IP address" that the web crawler is using. If all of that is correct, then the function will return "true".
Can you fake a Googlebot yourself?
Heck yes! Its pretty easy as well. Just follow this tutorial. Then use the following for your "user agent" to mimic a Googlebot:
curl -A "'Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)')" http://MYDOMAIN.COM/ --head
Thanks for reading!
I hope you enjoyed this blog post on why fake Googlebots exist, and how to detect them. See you again soon :)
Conversation:
No comments yet. Please contribute to the conversation and leave a comment below.
Conversation:
Ever since building my first website in 2002, I've been hooked on web development. I now manage my own network of eCommerce/content websites full-time. I'm also building a cabin inside a old ghost town. This is my personal blog, where I discuss web development, SEO, cabin building, and other personal musings.
